
README-es.md 14KB
Arreglos - Ley de Benford
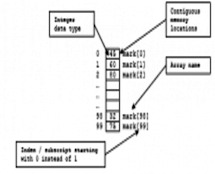

Los arreglos de datos (arrays) nos facilitan guardar y trabajar con grupos de datos del mismo tipo. Los datos se guardan en espacios de memoria consecutivos a los que se puede acceder utilizando el nombre del arreglo e índices o suscritos que indican la posición en que se encuentra el dato. Las estructuras de repetición nos proveen una manera simple de acceder a los datos de un arreglo. En la experiencia de laboratorio de hoy practicarás el uso de contadores y arreglos de una dimensión para implementar un programa en el que usarás la Ley de Benford para detectar archivos con datos falsificados.
Objetivos:
Practicar el uso de un arreglo de contadores para determinar la frecuencia de los datos de un archivo.
Detectar el uso de datos falsificados utilizando la distribución de frecuencia y la Ley de Benford.
Practicar la lectura de datos de un archivo de texto.
Pre-Lab:
Antes de llegar al laboratorio debes haber:
Aprendido cómo extraer el dígito líder (primer dígito) de un número entero leído de un archivo.
Repasado los conceptos relacionados a arreglos y contadores.
Repasado cómo leer datos de un archivo en C++.
Estudiado los conceptos e instrucciones para la sesión de laboratorio.
Tomado el quiz Pre-Lab, disponible en Moodle.
Como parte de tu nuevo trabajo de auditora de tecnología de información, tienes la sospecha de que alguien en la Autoridad Metropolitana de Autobuses (AMA) de Puerto Rico ha estado manipulando los sistemas de información y cambiando los archivos de datos que contienen los totales de pasajeros de las rutas diarias de las guaguas. Te han dado cinco archivos de texto que contienen los totales diarios de cada una de las rutas de las guaguas de la AMA y debes determinar si uno o más archivos contienen datos falsos. Para detectar cuál(es) archivos tienen datos falsos implementarás un programa en el que usarás la Ley de Benford.
¿Qué es la Ley de Benford? (adaptado del ISACA Journal [1])
La Ley de Benford es la teoría matemática de los dígitos líderes de un número, y fue llamada así en honor al físico Frank Benford, quien trabajó en esta teoría en 1938. Específicamente, en conjuntos de datos, los dígitos líderes están distribuidos de forma no uniforme. Uno podría pensar que el número 1 aparece como primer dígito el 11% del tiempo (esto es, uno de 9 números posibles), sin embargo, este número aparece como líder alrededor del 30% del tiempo (vea la Figura 1). Por otro lado, el número 9 es el primer dígito menos del 5% del tiempo. La teoría cubre las ocurrencias del primer dígito, el segundo dígito, los primeros dos dígitos, el último dígito y otras combinaciones de dígitos porque la teoría está basada en un logaritmo de probabilidad de ocurrencia de dígitos.
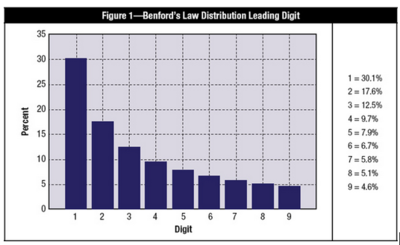
Figura 1. Distribución del primer dígito en un conjunto de datos real según la Ley de Benford. Tomado de [1].
Cómo usar la Ley de Benford para detectar datos falsificados
En esta experiencia de laboratorio usarás la Ley de Benford aplicada solamente al primer dígito (el dígito líder). Para hacer esto, necesitas determinar la frecuencia de cada dígito líder en los números en un archivo. Supón que te dan un archivo que contiene los siguientes números enteros:
890 3412 234 143 112 178 112 842 5892 19
777 206 156 900 1138 438 158 978 238 192
Según vas leyendo cada número $$n$$, determinas su dígito líder (la manera de extraer el dígito líder de un número se deja como un ejercicio para tí). También debes estar pendiente de cuántas veces sale el dígito líder en el conjunto de datos. La manera más fácil de llevar cuenta de la cantidad de veces que aparece el 1 como líder, el 2 como líder, … , el 9 como líder, es utilizando un arreglo de contadores. Este arreglo de contadores es sencillamente un arreglo de enteros en el que un elemento del arreglo se incrementa cada vez que se encuentra cierto dígito líder. Por ejemplo, para este ejercicio el arreglo de contadores puede ser un arreglo de 10 enteros, inicializado a 0.
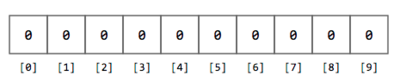
Figura 2. Arreglo de 10 enteros inicializado a 0.
Cada vez que se encuentra el dígito líder d, el elemento con índice d se incrementa. Por ejemplo, luego de leer los números 890 3412 234 143 112, el contenido del arreglo sería el siguiente:

Figura 3. Contenido del arreglo luego de leer 890 3412 234 143 112, y contar sus dígitos líderes.
Al finalizar de examinar el archivo, el contenido de cada elemento en el arreglo será el número de veces que el dígito líder aparece en los datos.
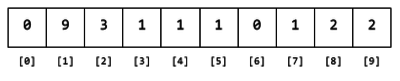
Figura 4. Contenido del arreglo de contadores luego de examinar todos los datos.
Frecuencia de ocurrencia
La frecuencia de ocurrencia se define como la razón del número de veces que un dígito aparece sobre el número total de datos. Por ejemplo, la frecuencia del dígito líder 1 en el ejemplo de la Figura 4 se computa como $$9/20 = 0.45$$. La manera común de visualizar las distribuciones de frecuencia de un conjunto de datos es utilizando un histograma. En esencia, un histograma es una gráfica de barras en la que el eje de $$y$$ es la frecuencia de ocurrencia y se dibuja una barra para cada una de las clasificaciones que se cuenta (en nuestro caso, una barra para cada dígito líder).
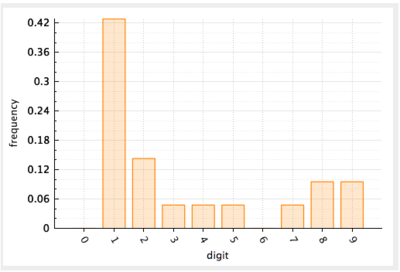
Figura 5. Histograma para la frecuencia de los dígitos líderes en los datos de muestra.
Leyendo datos de un archivo de texto en C++
En este laboratorio crearás un programa que lee datos de un archivo de texto. Puedes saltar esta sección si te sientes cómodo con tus destrezas de manejo de archivos de texto en C++. De lo contrario, siga leyendo…
C++ provee funciones para leer y escribir datos en archivos. En este laboratorio usarás uno de los métodos más básicos de lectura: lectura secuencial de archivos de texto. Los archivos de texto consisten de caracteres ASCII que representan datos en alguno de los tipos primitivos de C++. Típicamente, los valores están separados por espacios. Por ejemplo, supón que el archivo nameAge.txt contiene algunos datos sobre nombres y edades.
Tomas 34
Marta 55
Remigio 88
Andrea 43
Para leer un archivo de texto como parte de un programa en C++, debemos conocer cómo están organizados los datos en el archivo y qué tipo de datos deseamos leer. El archivo ejemplo nameAge.txt contiene cuatro líneas y cada línea contiene un string y un entero. A continuación un programa para leer el archivo de principio a fin mientras se imprimen los datos que se van leyendo en cada línea. Lee los comentarios del programa para entiendas sus partes:
#include <iostream>
// fstream es el header file que contiene clases, funciones y objetos
// para trabjar con lectura y escritura de archivos.
#include <fstream>
using namespace std;
int main(){
// Usaremos las siguientes dos variables para asignarle los
// valores que leemos en cada linea del archivo.
string name;
int age;
// Definimos el objeto que representará al archivo
ifstream inFile;
// Invocamos a la funcion open para que abra el file `nameAge.txt`
inFile.open("nameAge.txt");
// Verificamos que el archivo ha sido debidamente abierto
if (!inFile.is_open()) {
cout << "Error openning file nameAge.txt\n";
exit(1);
}
// Mientras haya datos por leer en el archivo, leer un string
// y un entero. Observa como usamos simbolo `>>`, parecido
// a como lo usamos con cin.
while (inFile >> name >> age) {
cout << name << " : " << age << endl;
}
// Cerrar el archivo.
inFile.close();
return 0;
}
El objeto ifstream permite que leamos el archivo de forma secuencial. Lleva cuenta de la próxima posición a leer dentro del archivo. Cada vez que leemos uno o más datos (usando inFile >> ____) el objeto adelanta su posición para que el próximo inFile >> ___ pueda leer los datos siguientes.
Observa la linea inFile >> name >> age. Esa instrucción realiza varias tareas:
- Lee un string y un int del archivo (si queda algo por leer) y se los asigna a las variables
nameyage. - Si pudo leer ambos datos, la expresión
inFile >> name >> ageevalúatrue. - De lo contrario, la expresión evalúa
false, saliendo del bloque while.
A continuación algunos pedazos de código C++ para tareas comunes de lectura de archivos. Observa que en todas ellas:
- Creamos un objecto de clase
ifstream, llamamos a su funciónopeny verificamos que el archivo abrió correctamente. - Creamos una o más variables para asignarles los valores que leeremos del archivo.
- Implementamos un ciclo que se repite mientras hayan datos que leer del archivo.
- Cerramos el archivo.
Ejemplo 1: Leer un archivo que solo contiene datos enteros y acumular sus valores.
ifstream inFile;
int n;
int accum = 0;
inFile.open("nums.txt");
if (!inFile.is_open()) {
cout << "Error openning file nums.txt\n";
exit(1);
}
while (inFile >> n) {
accum = accum + n;
}
cout << "Total: " << accum << endl;
inFile.close();
Ejemplo 2: Contar el número de líneas en un archivo que contiene un nombre por línea. Luego imprimir el contenido de la línea del medio.
ifstream inFile;
string name;
int ctr = 0;
inFile.open("names.txt");
if (!inFile.is_open()) {
cout << "Error openning file names.txt\n";
exit(1);
}
while (inFile >> name) {
ctr++;
}
cout << "Total number of lines: " << ctr << endl;
// Estos dos comandos retroceden el file al principio.
inFile.clear();
inFile.seekg(0);
for (int i = 0; i <= ctr / 2; i++) {
inFile >> name;
}
cout << "The name at the position " << ctr / 2 << ": " << name << endl;
inFile.close();
!INCLUDE “../../eip-diagnostic/benfords-law/es/diag-benford-law-01.html”
!INCLUDE “../../eip-diagnostic/benfords-law/es/diag-benford-law-02.html”
!INCLUDE “../../eip-diagnostic/benfords-law/es/diag-benford-law-03.html”
!INCLUDE “../../eip-diagnostic/benfords-law/es/diag-benford-law-04.html”
Sesión de laboratorio:
Ejercicio 1: Entender los archivos de datos y el código provisto
Instrucciones
Carga a
QtCreatorel proyectoBenfordsLaw. Hay dos maneras de hacer esto:Utilizando la máquina virtual: Haz doble “click” en el archivo
BenfordsLaw.proque se encuentra en el directorio/home/eip/labs/arrays-benfordslawde la máquina virtual.Descargando la carpeta del proyecto de
Bitbucket: Utiliza un terminal y escribe el commandogit clone http:/bitbucket.org/eip-uprrp/arrays-benfordslawpara descargar la carpetaarrays-benfordslawdeBitbucket. En esa carpeta, haz doble “click” en el archivoBenfordsLaw.pro.
Los archivos de datos
cta-a.txt,cta-b.txt,cta-c.txt,cta-d.txt, ycta-e.txten el directoriodatacontienen datos reales o datos falsos. Cada línea del archivo especifica el código de una ruta de guagua seguido por el número de personas que usaron la guagua en cierto día. Abre el archivocta-a.txtpara que entiendas el formato de los datos. Esto será importante cuando leas los datos desde tu programa. Nota que algunos de los códigos de ruta contienen caracteres.Abre el archivo
main.cpp. Estudia la funciónmainpara que te asegures de que entiendes todas las partes. En esencia, la funciónmainque te proveemos crea una pantalla y dibuja un histograma parecido al que se muestra en la Figura 6.
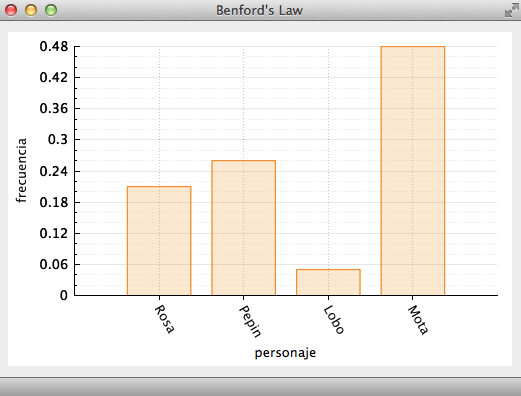
Figura 6. Ventana del resultado del ejemplo provisto en el proyecto
BenfordLaw. Se despliega un histograma utilizando los datos de los argumentoshistoNamesehistoValues.
Nota que los datos para los arreglos
histoNamesehistoValuesutilizados en la invocación al métodohistofueron asignados directamente en la declaración de cada arreglo. Para cada uno de los archivos en el directoriodata, tu programa deberá computar la frecuencia de ocurrencia de los dígitos líderes y luego desplegar su histograma utilizando el métodohisto.
Ejercicio 2: Implementar código para detectar datos falsificados en un archivo
Instrucciones
Utilizando como inspiración la función
mainque te proveemos, añade funcionalidad a la funciónmainpara leer archivos como los provistos en el directoriodatay determinar la frecuencia de ocurrencia de dígitos líderes en los datos que aparecen en la segunda columna de los archivos. Computa la frecuencia de ocurrencia como se explica antes de la Figura 5.Una vez tu programa haya obtenido las frecuencias de los dígitos líderes, utiliza el método
histopara desplegar un histograma. Corre el programa para cada uno de los archivos. Basado en la gráfica de distribución de frecuencia de los dígitos líderes en los datos en cada uno de los archivos, podrás determinar si (de acuerdo a la Ley de Benford) el archivo contiene datos reales o datos falsos.
Entregas
Utiliza “Entrega 1” en Moodle para entregar el archivo
main.cppque modificaste en el Ejercicio 2. Recuerda utilizar buenas prácticas de programación, incluir el nombre de los programadores y documentar tu programa.Utiliza “Entrega 2” en Moodle para entregar un archivo pdf que muestre fotos de los histogramas para cada uno de los archivos. Por favor, subtitula cada figura especificando el archivo que se utilizó para generarla y tu decisión sobre si el archivo contiene data real o falsificada.