
README-en.md 14KB
Arrays - Sound Processing
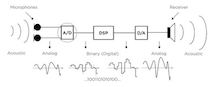
Arrays help us store and work with groups of data of the same type. The data is stored in consecutive memory spaces, which can be accessed by using the name of the array with indexes or subscripts that indicate the position where the data is stored. Repetition structures provide us a simple way of accessing the data within an array. In this laboratory experience, you will be exposed to simple sound processing algorithms in order to practice the use of loops to manipulate arrays.
This laboratory experience is an adaptation of the nifty assignment presented by Daniel Zingaro in [1].
Objectives
Practice the use of loops to manipulate arrays.
Learn simple algorithms to process sound.
Practice modular programming.
Pre-Lab:
Before coming to the laboratory you should have:
Reviewed the basic concepts related to arrays and loops.
Studied the
leftandrightattributes of theQAudioBuffer::S16Sclass in theQtmultimedia library.Studied the concepts and instructions for the laboratory session.
Taken the Pre-Lab quiz, available in Moodle.
Digital Sound Processing
Sounds are vibrations that propagate through elastic media such as air, water, and solids. The sound waves are generated by a sound source, such as the vibrating diaphragm of a stereo speaker [2]. Sound waves consist of areas of high and low pressure called compressions and rarefractions, respectively.
Microphones turn sound waves into electrical signals. These electrical signals can be digitized, i.e. converted to a stream of numbers, where each number is the intensity of the electrical signal at an instant in time. The sample rate is the number of samples of a sound signal taken per second. For example, a sample rate of 44,100 samples per second is used in CD-quality recordings. This means that every second, for each of the channels (left and right), 44,100 samples of the audio signal are taken and converted to numbers.
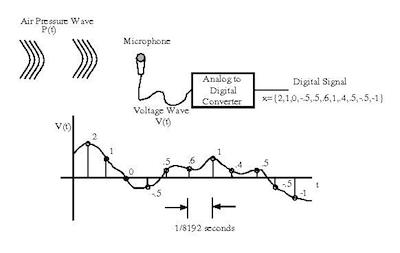
Figure 1: Illustration of the steps involved in sound digitalization. The pressure wave is converted to a voltage signal by the microphone. The voltage signal is sampled and digitized by the analog to digital converter to obtain a number value for each sample. The stream of numbers constitutes the digitized sound. [3]
Question:
How many bytes would it take to store a song that is exactly 180 seconds long and is recorded in stereo CD-quality? Assume that each sample is converted to a number of 2 bytes.
Answer:
$$180 \,\text{seconds} \times 44,100 \,\text{samples/second} \times 2 \,\text{bytes/sample} \times 2 \,\text{channels} $$
$$= 31,752,000 \,\text{bytes} = 31.75 \,\text{MBytes}$$
Fortunately, there is sound data compression techniques such as MP3 and Ogg, that reduce the amount of memory required to store CD-quality music.
Digital sound processing techniques can be used to enhance sound quality by removing noise and echo, to perform data compression, and to improve transmission. Digital sound processing also plays an important role in voice recognition applications and in scientific research such as in biodiversity recognition using sound sensors [4]. Digital sound can also be easily manipulated to produce special effects.
Since digital sound recordings are in essence, a collection of numeric values that represent a sound wave, digital sound processing can be as simple as applying arithmetic operations over those values. For example, let’s say that you are given a digital sound recording; the louder the recording, the higher the absolute values of the numbers that it contains. To decrease the volume of the whole recording we could multiply each value by a positive number smaller than 1.
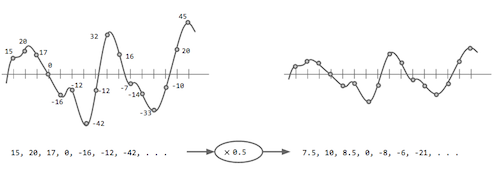
Figure 2. One of the simplest sound processing tasks: changing the volume of a sound wave by multiplying each point by a positive number smaller than 1 (in this case 0.5).
Libraries
For this laboratory experience you will use the multimedia libraries of Qt. To complete the exercises, you will need to understand the left and right members of the QAudioBuffer::S16S class. For the purpose of this laboratory experience, we use the name AudioBuffer to refer to QAudioBuffer::S16S.
Each object of the class AudioBuffer will have the variable members left and right that contain the left and right values of the stereo sound sample. These variables are public and you can access their content by writing the name of the object, followed by a period and the name of the variable. To represent a sound signal, we use an array of AudioBuffer objects. Each element in the array is an object that contains the left and right values of the signal at an instant in time (remember that each second contains 44,100 samples). For instance, if we have an array of AudioBuffer objects, called frames, then frames[i].left refers to the left channel value of the sound at sample i.
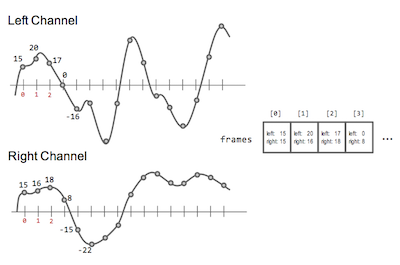
Figure 3. In the figure, frame is an array of AudioBuffer objects. During this laboratory experience, sound signals will be represented by an array of AudioBuffer objects. An object with index i stores the values of the left and right channels of sample i.
The HalfVolume function in the following example illustrates how to read and modify an array of AudioBuffer objects:
// Given frames (an array of AudioBuffers) and N (its size)
// divide each sample by two (both the left and right channels).
void HalfVolume(AudioBuffer frames[], int N){
// for each sample in the signal, reduce its value to half
for (int i=0; i < N; i++) {
frames[i].left = frames[i].left / 2;
frames[i].right = frames[i].right / 2;
}
}
!INCLUDE “../../eip-diagnostic/sound-processing/en/diag-sound-processing-01.html”
!INCLUDE “../../eip-diagnostic/sound-processing/en/diag-sound-processing-02.html”
!INCLUDE “../../eip-diagnostic/sound-processing/en/diag-sound-processing-03.html”
!INCLUDE “../../eip-diagnostic/sound-processing/en/diag-sound-processing-04.html”
Laboratory Session:
The SoundProcessing project contains the skeleton of an application to process stereo sound. The application you will complete will allow the user to apply four different algorithms to process sound. The sub-directory called WaveSamples contains sound files for you to test your implementations.
Exercise 1 - Remove Vocals on a Recording
A cheap (but many times ineffective) way to remove the vocals from a recording is by taking advantage of the fact that voice is commonly recorded in both left and right channels, while the rest of the instruments may not. If this is the case, then we can remove vocals from a recording by subtracting the left and right channels.
Instructions
Load the project
SoundProcessingintoQtCreator. There are two ways to do this:- Using the virtual machine: Double click the file
SoundProcessing.prolocated in the folder/home/eip/labs/arrays-soundprocessingof your virtual machine. - Downloading the project’s folder from
Bitbucket: Use a terminal and write the commandgit clone http://bitbucket.org/eip-uprrp/arrays-soundprocessingto download the folderarrays-soundprocessingfromBitbucket. Double click the fileSoundProcessing.prolocated in the folder that you downloaded to your computer.
- Using the virtual machine: Double click the file
Compile and run the program. You will see a graphical interface to process sound and recordings.
Load any of the wave files
love.wav,cartoon.wav, orgrace.wavby clicking theSearchbutton in the right side of theAudio Inlabel, and play it clicking thePlay Audio Inbutton.In this exercise, your task is to complete the function
RemoveVocalsin fileaudiomanip.cppso it can remove voices from a recording. The function receives an array of objects of the classAudioBuffer, and the size of the array.
Algorithm:
For each sample in the array, compute the difference of the sample’s left channel minus its right channel, divide it by 2, and use this value as the new value for both the left and right channels of the corresponding sample.
Play the output sound file with the application by clicking the Play Audio Out button.
Exercise 2 - Fade In
A common sound effect is the gradual intensification of the recording’s volume, or fade in. This is the result of constantly increasing the value of consecutive samples in the array of sound samples.
Instructions
Load and play any of the wave files
rain.wav, orwater.wavjust as in Exercise 1.Your task is to complete the function
AudioFadeInin fileaudiomanip.cppso it gradually intensifies the volume of a recording up to a certain moment. The function receives an array of objects of the classAudioBuffer, the size of the array, and a fade in length that will be applied to theAudioBuffer. For example, iffade_lengthis88200, the fade in should not affect any sample in position88200or higher.Reproduce the following recordings from the
WaveSamplesfolder:rain-fi.wavwater-fi.wav
These two recordings were created using the fade in filter with fade_length set to 88200. You should be able to listen how the water and the rain linearly fades in over the first two seconds, and then remains at the same volume throughout the recording. Notice that, since we are using sounds recorded at 44100 samples per second, 88200 corresponds to two seconds of the recording.
Algorithm:
To apply a fade-in to a sound, we multiply successive samples by constantly increasing fractional numbers between 0 and 1. Multiplying samples by 0 silences them, and multiplying by 1 keeps them the same; multiplying by a factor between 0 and 1 scales their volume by that factor. It’s important to mention that both channels of the samples should be multiplied by the same factor.
For instance, if fade_length is 4, the filter will be applied to the first 4 samples:
| Sample Number | Multiply by factor |
|---|---|
| 0 | 0 |
| 1 | 0.25 |
| 2 | 0.5 |
| 3 | 0.75 |
| >= 4 | 1 (Do not modify the sample) |
Notice that we have 4 samples and the factor used to multiply the sample in each channel stars at 0 and increases 0.25 each time until reaching 1.
Exercise 3 - Fade Out
Another common sound effect is the gradual decrease of volume in a recording. This is the result of constantly decreasing the value of consecutive samples in the array of sound samples.
Instructions
Load and play any of the wave files
rain.wav, orwater.wavjust like in the previous exercises.Your task in this exercise is to complete the function
AudioFadeOutin the fileaudiomanip.cppso it will fade out the volume during the end of the recording. The function receives an array of objects of the classAudioBuffer, the size of the array, and a fade-out length that will be applied to theAudioBuffer. For example, iffade_lengthis88200, the fade-out will begin88200samples from the end of the recording .Reproduce the following recordings from the
WaveSamplesfolder:rain.fo.wavwater.fo.wav
These two recordings were created using the fade out filter with fade_length set to 88200. You should be able to listen how the water and the rain is played at maximum volume and then in the last two seconds the sound starts to linearly fade out.
Algorithm:
The multiplicative factors for fade_out are the same as for fade_in, but are applied in the reverse order. For example, if fade_length were 4, the samples in the fourth-before-last positions would be multiplied by 0.75 (in both channels), the samples in the third-before-last positions would be multiplied by 0.5, the samples in the penultimate positions would be multiplied by 0.25, the samples in the final positions would be multiplied by 0.0.
Exercise 4 - Panning from Left to Right
The sound effect we want to produce in this exercise is to start hearing sound from the left channel, then fading from that channel, intensifying in the right channel, and ending up completely on the right channel.
Instructions
Load and play the
airplane.wavjust like in the previous exercises.Your task is to complete the function
LeftToRightin fileaudiomanip.cppso the sound “moves” from the left channel to the right channel. The function receives an array of objects of classAudioBuffer, the size of the array, and a pan length that will be applied to theAudioBuffer. For example, ifpan_lengthis88200, the pan should not affect any sample in position88200or higher.Play the
airplane.out.wavrecording. You should be able to listen how the airplane sound starts completely at the left, then slowly moves to the right, reaching the extreme right by the final sample. In this example the panning finishes in the last sample. This will not happen if the panning length is not equal to the number of samples; in this case, after reaching the panning length you will listen the normal sound in both channels.
Algorithm:
Getting a sound to move from left to right like this requires a fade-out on the left channel and a fade-in on the right channel. For instance, if pan_length is 4, the filter will be applied to the first 4 samples:
| Sample Number | Multiply left channel by factor | Multiply right channel by factor |
|---|---|---|
| 0 | 0.75 | 0 |
| 1 | 0.5 | 0.25 |
| 2 | 0.25 | 0.5 |
| 3 | 0 | 0.75 |
| >= 4 | (Do not modify the sample) | (Do not modify the sample) |
Deliverables
Use “Deliverable” in Moodle to upload the audiomanip.cpp file. Remember to use good programming techniques, include the names of the programmers involved, and document your program.
References
[1] Daniel Zingaro, http://nifty.stanford.edu/2012/zingaro-stereo-sound-processing/
[2] http://en.wikipedia.org/wiki/Sound
[3] http://homepages.udayton.edu/~hardierc/ece203/sound_files/image001.jpg.
{kind=link}
[4] Arbimon, A web based network for storing, sharing, and analyzing acoustic information. http://arbimon.com/
[5] https://somnathbanik.wordpress.com/2012/10/22/digital-signal-processing-featured-project/
[7] http://diveintodotnet.com/2014/12/02/programming-basics-what-are-strings/