
 Jose Ortiz
86d0580d6d
initial commit
Jose Ortiz
86d0580d6d
initial commit
|
10 år sedan | |
|---|---|---|
| WaveSamples | 10 år sedan | |
| doc | 10 år sedan | |
| images | 10 år sedan | |
| README.md | 10 år sedan | |
| Sounds.pro | 10 år sedan | |
| Sounds.pro.user | 10 år sedan | |
| audio.rsc | 10 år sedan | |
| audiomanip.cpp | 10 år sedan | |
| audiomanip.h | 10 år sedan | |
| images.qrc | 10 år sedan | |
| main.cpp | 10 år sedan | |
| mainwindow.cpp | 10 år sedan | |
| mainwindow.h | 10 år sedan | |
| mainwindow.ui | 10 år sedan | |
| wavesound.cpp | 10 år sedan | |
| wavesound.h | 10 år sedan |
README.md
Arreglos - Procesamiento de sonido
Los arreglos de datos (arrays) nos facilitan guardar y trabajar con grupos de datos del mismo tipo. Los datos se guardan en espacios de memoria consecutivos a los que se puede acceder utilizando el nombre del arreglo e índices o suscritos que indican la posición en que se encuentra el dato. Las estructuras de repetición nos proveen una manera simple de acceder a los datos de un arreglo. En la experiencia de laboratorio de hoy te expondrás a algoritmos de procesamiento de sonido, simples pero ingeniosos, para practicar el uso de ciclos en la manipulación de arreglos.
Esta experiencia de laboratorio es una adaptación de un “nifty assignment” presentado por Daniel Zingaro en [1].
Objetivos:
Practicar el uso de ciclos en la manipulación de arreglos.
Aprender algoritmos simples para procesar sonido.
Practicar la programación modular.
Pre-Lab:
Antes de llegar al laboratorio debes haber:
Repasado los conceptos relacionados a arreglos y ciclos.
Estudiado los atributos
leftyrightde la claseQAudioBuffer::S16Sde la librería multimedios deQt.Estudiado los conceptos e instrucciones para la sesión de laboratorio.
Tomado el quiz Pre-Lab que se encuentra en Moodle.
Procesamiento de sonido digital
El sonido es una vibración que se propaga en medios elásticos tales como el aire, el agua y los sólidos. Las ondas sonoras son generadas por una fuente de sonido como por ejemplo la vibración del diafragma de una bocina de sonido [2]. Las ondas de sonido consisten de segmentos de alta y baja presión llamados compresiones y rarefacciones respectivamente.
Los micrófonos convierten las ondas de sonido a señales eléctricas. Estas señales eléctricas pueden digitalizarse, o sea, pueden ser convertidas a sucesiones de números, en donde cada número representa la intensidad de la señal eléctrica en un momento en el tiempo. La razón de la muestra es el número de muestras de la señal de sonido tomadas en un segundo. Por ejemplo, para obtener la calidad de sonido de una grabación estéreo de CD se usa una razón de muestra de 44,100 muestras por segundo. Esto significa que en cada segundo, para cada uno de los canales (izquierdo y derecho), se toman 44,100 muestras de sonido y se convierten a números.
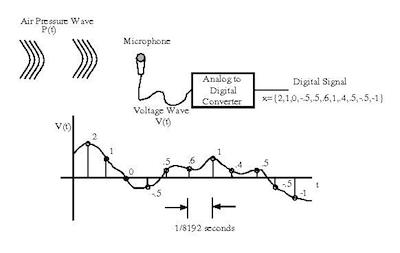
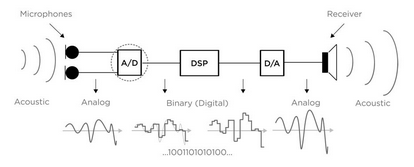
Figura 1. Ilustración de los pasos para realizar una digitalización de sonido. El micrófono convierte la onda de presión en una señal de voltaje. El convertidor de señal análoga a señal digital toma muestras de la señal de voltaje y convierte cada muestra en un valor numérico. La sucesión de números forma el sonido digitalizado. Tomado de [3].
Pregunta…
Supón que cada muestra de sonido se convierte a un número que ocupa 2 bytes. ?Cuántos bytes se necesitan para guardar una canción que dure exactamente 180 segundos y que fue grabada en calidad de CD estéreo?
Respuesta:
180 segundos * 44,100 muestras/segundo * 2 bytes/muestra * 2 canales = 31,752,000 bytes = 31.75 MBytes.
Afortunadamente existen técnicas de compresión de datos como MP3 y ogg que reducen la cantidad de memoria necesaria para guardar música con calidad de CD.
Las técnicas de procesamiento digital se pueden utilizar para mejorar la calidad del sonido removiendo ruido y eco para comprimir los datos y para mejorar la transmisión. El procesamiento de sonido digital también juega un papel importante en las aplicaciones de reconocimiento de voz y en investigaciones científicas de detección de biodiversidad utilizando sensores de sonido [4]. El sonido digital también se puede manipular fácilmente para lograr efectos especiales.
Como las grabaciones de sonido digital son esencialmente una colección de valores numéricos que representan una onda de sonido, el procesamiento de sonido digital puede ser tan simple como el aplicar operaciones aritméticas a esos valores. Por ejemplo, digamos que tienes una grabación de sonido digital. Mientras más alto el volúmen de la grabación, más altos los valores absolutos de los números que contiene. Para reducir el volúmen de toda la grabación solo tendríamos que multiplicar cada valor en la grabación por un número positivo menor que 1.
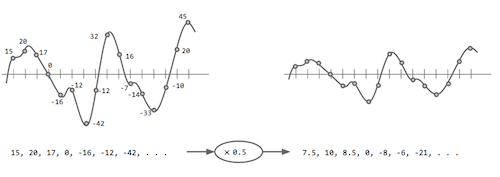
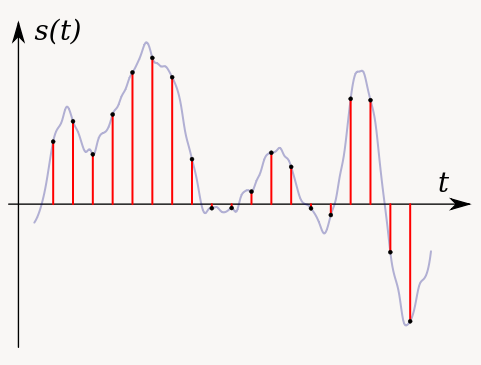
Figura 2. Una de las tareas más simples en el procesamiento de sonido digital: cambiar el volúmen de una onda de sonido multiplicando cada punto por un valor positivo menor que 1 (en este caso 0.5).
Bibliotecas
Para esta experiencia de laboratorio usarás bibliotecas multimedios de Qt. Para poder trabajar los ejercicios necesitarás conocer los atributos left y right de la clase QAudioBuffer::S16S. Para propósito de esta experiencia de laboratorio utilizamos el nombre AudioBuffer al referirnos a QAudioBuffer::S16S.
Cada objeto de la clase AudioBuffer tendrá atributos o variables miembro left y right que contienen el valor izquierdo y derecho de la muestra de sonido estéreo. Estas variables son públicas y podrás acceder su contenido escribiendo el nombre del objeto, seguido de un punto y luego el nombre de la variable. Para representar una señal de sonido, usamos un arreglo de objetos de clase AudioBuffer. Cada elemento del arreglo es un objeto que contiene los valores izquierdo y derecho de la señal en un instante en el tiempo (recuerda que cada segundo contiene 44,100 muestras). Por ejemplo, si tenemos un arreglo de objetos AudioBuffer, llamado frames, entonces frames[i].left se refiere al valor del canal izquierdo del sonido en la muestra i.
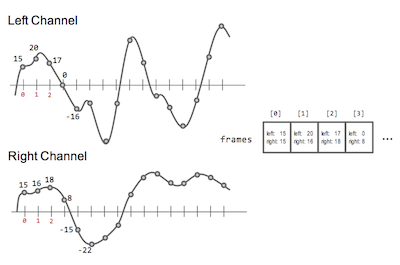
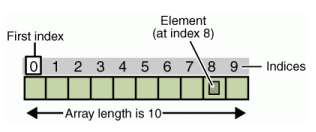
Figura 3. En la figura, frame es un arreglo de objetos AudioBuffer. En esta experiencia de laboratorio, las señales de sonido estarán representadas por un arreglo de objetos AudioBuffer. Un objeto con índice i guarda el valor de los canales izquierdo y derecho de la muestra i.
La función HalfVolume en el siguiente ejemplo ilustra cómo leer y modificar un arreglo de objetos AudioBuffer:
void HalfVolume(AudioBuffer frames[], int N){
// para cada muestra en la señal, reduce su valor a la mitad
for (int i=0; i < N; i++) {
frames[i].left = frames[i].left / 2;
frames[i].right = frames[i].right / 2;
}
}
Sesión de laboratorio:
El proyecto SoundProcessing contiene el esqueleto de una aplicación para hacer procesamiento de sonido estéreo. La aplicación que completarás permitirá al usuario aplicar cuatro algoritmos diferentes para procesamiento de sonidos. La sub-carpeta llamada WaveSamples contiene archivos de onda para que pruebes tus implementaciones.
Ejercicio 1: Remover las voces de una grabación
Una forma barata (pero muchas veces inefectiva) de remover las voces de una grabación es tomando ventaja del hecho de que las voces usualmente se graban en ambos canales, izquierdo y derecho, mientras que el resto de los instrumentos quizás no. Si este fuera el caso, podemos remover las voces de una grabación restando el canal izquierdo y derecho.
Instrucciones
Carga a
QtCreatorel proyectoSoundProcessinghaciendo doble “click” en el archivoSounds.proen el directorioDocuments/eip/Arrays-SoundProcessingde tu computadora. También puedes ir ahttp://bitbucket.org/eip-uprrp/arrays-soundprocessingpara descargar la carpetaArrays-SoundProcessinga tu computadora.Compila y corre el programa. Aparecerá un interface gráfico para procesamiento de sonido de grabaciones.
Carga cualquiera de los archivos de onda
love.wav,cartoon.wav, ograce.wavmarcando el botón de búsqueda (Search) en el lado derecho de la etiquetaAudio In, y reprodúcela marcando el botónPlay Audio In.Tu tarea en este ejercicio es completar la función
RemoveVocalsque se encuentra en el archivoaudiomanip.cpppara que remueva las voces de una grabación. La función recibe un arreglo de objetos de la claseAudioBuffery el tamaño del arreglo.
Algoritmo:
Para cada muestra en el arreglo, computa la diferencia de la muestra del canal izquierdo menos el derecho, divídelo por 2 y usa este valor como el nuevo valor para la muestra correspondiente en el canal izquierdo y derecho.
Marca el botón Play Audio Out en la aplicación para reproducir el sonido del archivo de salida.
Ejercicio 2: Intensificar
Un efecto de sonido común es la intensificación gradual del volumen de una grabación. Esto se consigue aumentando constantemente el valor de muestras consecutivas en el arreglo de muestras de sonido.
Instrucciones
Carga y reproduce cualquiera de los archivos de onda
rain.wav, owater.wavcomo hiciste en el Ejercicio 1.Tu tarea en este ejercicio es completar la función
AudioFadeInque se encuentra en el archivoaudiomanip.cppde modo que se intensifique gradualmente el volumen de una grabación hasta cierto punto. La función recibe un arreglo de objetos de la claseAudioBuffer, el tamaño del arreglo, y un largo de duración para el aumento en intensidad (fade_length) que será aplicado aAudioBuffer. Por ejemplo, sifade_lengthes88200, el aumento en intensidad no debe afectar ninguna muestra en posición mayor o igual a88200.Reproduce las siguientes grabaciones contenidas en la carpeta
WaveSamples:rain.fi.wavwater.fi.wav
Las grabaciones fueron creadas utilizando el filtro de intensidad con
fade_length 88200. Debes escuchar como el sonido del agua y la lluvia se intensifican linealmente durante los primeros dos segundos y luego se quedan en el mismo volúmen. Nota que, como estamos usando sonidos grabados a44100muestras por segundo,88200corresponde a dos segundos de grabación.
Algoritmo:
Para aplicar el aumento de intensidad a un sonido, multiplicamos cada muestra sucesiva por números entre 0 y 1 que van en aumento constante. Si la muestra se multiplica por 0 se silencia, si se multiplica por 1 se queda igual; si se multiplica por un valor entre 0 y 1 el volúmen se escala por ese factor. Ambos canales deben ser multiplicados por el mismo factor.
Por ejemplo, si fade_length es 4, aplicaremos el filtro a las primeras 4 muestras:
| Número de muestra | Multiplica por factor |
|---|---|
| 0 | 0 |
| 1 | 0.25 |
| 2 | 0.5 |
| 3 | 0.75 |
| >= 4 | 1 (No modifica la muestra) |
Nota que tenemos 4 muestras y el factor por el que se multiplica la muestra en cada canal comienza en 0 e incrementa 0.25 cada vez hasta llegar a 1.
Ejercicio 3: Desvanecer
Otro efecto de sonido común es la disminución gradual del volumen de una grabación. Esto se consigue disminuyendo constantemente el valor de muestras consecutivas en el arreglo de muestras de sonido.
Instrucciones
Carga y reproduce cualquiera de los archivos de onda
rain.wav, owater.wavcomo hiciste en los ejercicios anteriores.Tu tarea en este ejercicio es completar la función
AudioFadeOutque se encuentra en el archivoaudiomanip.cpppara que desvanezca el volúmen a partir de una muestra de la grabación hasta el final. La función recibe un arreglo de objetos de la claseAudioBuffer, el tamaño del arreglo, y un largo de duración del desvanecimiento que será aplicado aAudioBuffer. Por ejemplo, sifade_lengthes88200, el desvanecimiento no debe afectar ninguna muestra en posiciones menores o iguales a88200.Reproduce las siguientes grabaciones contenidas en la carpeta
WaveSamples:rain.fo.wavwater.fo.wav
Las grabaciones fueron creadas utilizando el filtro de desvanecer con
fade_length 88200. Debes escuchar el sonido del agua y la lluvia en volúmen constante y luego, en los últimos dos segundos, el volumen disminuye linealmente hasta desaparecer.
Algoritmo:
Los factores para desvanecer son los mismos que para intensificar pero se aplican en el orden opuesto. Por ejemplo, si fade_length fuera 4, las muestras de los canales en la posición cuatro antes de la última se multiplican por 0.75, las muestras de los canales en la posición tres antes de la última se multiplican por 0.5, las muestras de los canales en la penúltima posición se multiplican por 0.25, y las muestras en los canales en la última posición se multiplican por 0.0.
Ejercicio 4: Recorrido de izquierda a derecha
El efecto de sonido que queremos lograr en este ejercicio es comenzar a escuchar un sonido por el canal izquierdo, que vaya desvaneciéndose en ese canal, vaya intensificándose en el canal derecho y termine completamente en el canal derecho.
Instrucciones
Carga y reproduce el archivo
airplane.wavcomo hiciste en los ejercicios anteriores.Tu tarea en este ejercicio es completar la función
LeftToRightque se encuentra en el archivoaudiomanip.cpppara que haga que el sonido vaya “moviéndose” del canal izquierdo al canal derecho. La función recibe un arreglo de objetos de la claseAudioBuffer, el tamaño del arreglo, y un largo de recorrido (pan_length) que será aplicado aAudioBuffer. Por ejemplo, sipan_lengthes88200, el recorrido no debe afectar ninguna muestra en posiciones mayores o iguales a88200.Reproduce la grabación en
airplane.out.wav. Debes poder oir cómo el sonido del avión se escucha primero completamente a la izquierda y luego se mueve lentamente hacia la derecha, terminando completamente a la derecha en la última muestra.
Algoritmo:
Para crear el efecto de que el sonido se mueve de izquerda a derecha se necesita un desvanecimiento en el canal de la izquierda y una intensificación en el canal de la derecha. Por ejemplo, si el pan_length es 4, el filtro será aplicado a las primeras 4 muestras:
| Número de muestra | Factor a multiplicar por canal izquierdo | Factor a multiplicar por canal derecho |
|---|---|---|
| 0 | 0.75 | 0 |
| 1 | 0.5 | 0.25 |
| 2 | 0.25 | 0.5 |
| 3 | 0 | 0.75 |
| >= 4 | (No modificar la muestra) | (No modificar la muestra) |
Entrega
Utiliza “Entrega” en Moodle para entregar el archivo audiomanip.cpp. Recuerda utilizar buenas prácticas de programación, incluir el nombre de los programadores y documentar tu programa.
Referencias
[1] Daniel Zingaro, http://nifty.stanford.edu/2012/zingaro-stereo-sound-processing/
[2] http://en.wikipedia.org/wiki/Sound
[3] http://homepages.udayton.edu/~hardierc/ece203/sound_files/image001.jpg.
{kind=link}
[4] Arbimon, A web based network for storing, sharing, and analyzing acoustic information. http://arbimon.com/
[5] https://somnathbanik.wordpress.com/2012/10/22/digital-signal-processing-featured-project/
[7] http://diveintodotnet.com/2014/12/02/programming-basics-what-are-strings/
Arrays - Sound Processing
Arrays help us to store and work with groups of data of the same type. The data is stored in consecutive memory spaces which can be accessed by using the name of the array and indexes or subscripts that indicate the position where the data is stored. Repetition structures provide us a simple way of accessing the data within an array. In this laboratory experience, you will be using nested loops to process bi-dimensional arrays and implement the functionality of a green-screen.
This laboratory experience is an adaptation of the nifty assignment presented by Daniel Zingaro in [1].
Objectives
Practice the use of loops to manipulate arrays.
Learn simple algorithms to process sound.
Practice modular programming.
Pre-Lab:
Before coming to the laboratory you should have:
Reviewed the basic concepts related to arrays and loops.
Studied the
leftandrightattributes of theQAudioBuffer::S16Sclass in theQtmultimedia library.Studied the concepts and instructions for the laboratory session.
Taken the Pre-Lab quiz that is found in Moodle.
Digital Sound Processing
Sounds are vibrations that propagate through elastic media such as air, water, and solids. The sound waves are generated by a sound source, such as the vibrating diaphragm of a stereo speaker [2]. Sound waves consist of areas of high and low pressure called compressions and rarefractions, respectively.
Microphones convert sound waves into electrical signals. These electrical signals can be digitized, i.e. converted to a stream of numbers, where each number is the intensity of the electrical signal at an instant in time. The sample rate is the number of samples of a sound signal taken per second. For example, a sample rate of 44,100 samples per second is used in CD-quality recordings. This means that every second, for each of the channels (left and right), 44,100 samples of the audio signal are taken and converted to numbers.
Figure 1: Illustration of the steps involved in sound digitalization. The pressure wave is converted to a voltage signal by the microphone. The voltage signal is sampled and digitized by the analog to digital converter to obtain a number value for each sample. The stream of numbers constitutes the digitized sound. Taken from [3].
Question…
How many bytes would it take to store a song that is exactly 180 seconds long and that is recorded in stereo CD-quality. Assume that each sample is converted to a number of 2 bytes.
Answer:
180 seconds * 44,100 samples/second * 2 bytes/sample * 2 channels = 31,752,000 bytes = 31.75 MBytes.
Fortunately, there exist sound data compression techniques such as MP3 and ogg that reduce the amount of memory required to store CD-quality music.
Digital sound processing techniques can be used to enhance sound quality by removing noise and echo to perform data compression and to improve transmission. Digital sound processing also plays an important role in voice recognition applications and in scientific research such as in biodiversity recognition using sound sensors [4]. Digital sound can also be easily manipulated to produce special effects.
Since digital sound recordings are in essence a collection of numeric values that represent a sound wave, digital sound processing can be as simple as applying arithmetic operations over those values. For example, let’s say that you are given a digital sound recording. The louder the recording, the higher the absolute values of the numbers that it contains. To decrease the volume of the whole recording we could multiply each value by a positive number smaller than 1.
Figure 2. One of the simplest sound processing tasks: changing the volume of a sound wave by multiplying each point by a positive number smaller than 1 (in this case 0.5).
Libraries
For this laboratory experience you will use the multimedia libraries of Qt. To complete the exercises, you will need to understand the left and right members of the QAudioBuffer::S16S class. For the purpose of this laboratory experience we use the name AudioBuffer to refer to QAudioBuffer::S16S.
Each object of class AudioBuffer will have the variable members left and right that contain the left and right values of the stereo sound sample. These variables are public and you can access their content by writing the name of the object, followed by a period and the name of the variable. To represent a sound signal, we use an array of AudioBuffer objects. Each element in the array is an object that contains the left and right values of the signal at an instant in time (remember that each second contains 44,100 samples). For instance, if we have an array of AudioBuffer objects, called frames, then frames[i].left refers to the left channel value of the sound at sample i.
Figure 3. In the figure, frame is an array of AudioBuffer objects. During this laboratory experience, sound signals will be represented by an array of AudioBuffer objects. An object with index i stores the values of the left and right channels of sample i.
The HalfVolume function in the following example illustrates how to read and modify an array of AudioBuffer objects:
void HalfVolume(AudioBuffer frames[], int N){
// for each sample in the signal, reduce its value to half
for (int i=0; i < N; i++) {
frames[i].left = frames[i].left / 2;
frames[i].right = frames[i].right / 2;
}
}
Laboratory Session:
The SoundProcessing project contains the skeleton of an application to process stereo sound. The application you will complete will allow the user to apply four different algorithms to process sound. The sub-directory called WaveSamples contains sound files for you to test your implementation.
Exercise 1: Remove vocals on a recording
A cheap (but many times ineffective) way to remove the vocals from a recording is by taking advantage of the fact that voice is commonly recorded in both left and right channels, while the rest of the instruments may not. If this is the case, then we can remove vocals from a recording by subtracting the left and right channels.
Instructions
Load the project
SoundProcessingontoQtCreatorby double clicking on theSounds.profile in theDocuments/eip/Arrays-SoundProcessingdirectory on your computer. You may also go tohttp://bitbucket.org/eip-uprrp/arrays-soundprocessingto download theArrays-SoundProcessingfolder to your computer.Compile and run the program. You will see a graphical interface to process sound and recordings.
Load any of the wave files
love.wav,cartoon.wav, orgrace.wavby clicking theSearchbutton in the right side of theAudio Inlabel, and play it clicking thePlay Audio Inbutton.In this exercise, your task is to complete the function
RemoveVocalsin fileaudiomanip.cppso it can remove voices from a recording. The function receives an array of objects of classAudioBuffer, and the size of the array.
Algorithm:
For each sample in the array, compute the difference of the sample’s left channel minus its right channel, divide it by 2, and use this value as the new value for both the left and right channels of the corresponding sample.
Play the output sound file with the application by clicking the Play Audio Out button.
Exercise 2: Fade In
A common sound effect is the gradual intensification of the recording’s volume, or fade in. This is the result of constantly increasing the value of consecutive samples in the array of sound samples.
Instructions
Load and play any of the wave files
rain.wav, orwater.wavjust as in Exercise 1.Your task is to complete the function
AudioFadeInin fileaudiomanip.cppso it gradually intensifies the volume of a recording up to a certain moment. The function receives an array of objects of classAudioBuffer, the size of the array, and a fade in length that will be applied to theAudioBuffer. For example, iffade_lengthis88200, the fade in should not affect any sample in position88200or higher.Reproduce the following recordings from the
WaveSamplesfolder:
rain-fi.wavwater-fi.wav
The recordings were created using the fade in filter with fade_length set to 88200. You should be able to listen how the water and the rain linearly fades in over the first two seconds, and then remains at the same volume throughout. Notice that, since we are using sounds recorded at 44100 samples per second, 88200 corresponds to two seconds of the recording.
Algorithm:
To apply a fade in to a sound, we multiply successive samples by constantly increasing fractional numbers between 0 and 1. Multiplying samples by 0 silences them, and multiplying by 1 keeps them the same; multiplying by a factor between 0 and 1 scales their volume by that factor. Both channels of the samples should be multiplied by the same factor.
For instance, if fade_length is 4, the filter will be applied to the first 4 samples:
| Sample Number | Multiply by factor |
|---|---|
| 0 | 0 |
| 1 | 0.25 |
| 2 | 0.5 |
| 3 | 0.75 |
| >= 4 | 1 (Do not modify the sample) |
Notice that we have 4 samples and the factor used to multiply the sample in each channel stars at 0 and increases 0.25 each time until reaching 1.
Exercise 3: Fade Out
Another common sound effect is the gradual decrease of volume in a recording. This is the result of constantly decreasing the value of consecutive samples in the array of sound samples.
Instructions
Load and play any of the wave files
rain.wav, orwater.wavjust like in the previous exercises.Your task in this exercise is to complete the function
AudioFadeOutin the fileaudiomanip.cppso it will fade out the volume starting from a sample up to the end of the recording. The function receives an array of objects of classAudioBuffer, the size of the array, and a fade out length that will be applied to theAudioBuffer. For example, iffade_lengthis88200, the fade-out should not affect any sample numbered88200or lower.Reproduce the following recordings from the
WaveSamplesfolder:
rain.fo.wavwater.fo.wav
The recordings were created using the fae out filter with fade_length set to 88200. You should be able to listen how the water and the rain is played at maximum volume and then in the last two seconds the sound starts to linearly fade out.
Algorithm:
The multiplicative factors for fade_out are the same as for fade_in, but are applied in the reverse order. For example, if fade_length were 4, the samples in the fourth-before-last positions would be multiplied by 0.75 (in both channels), the samples in the third-before-last positions would be multiplied by 0.5, the samples in the penultimate positions would be multiplied by 0.25, the samples in the final positions would be multiplied by 0.0.
Exercise 4: Panning from left to right
The sound effect we want to produce in this exercise is to start hearing sound from the left channel, then fading from that channel, intensifying in the right channel and ending up completely on the right channel.
Instructions
Load and play the
airplane.wavjust like in the previous exercises.Your task is to complete the function
LeftToRightin fileaudiomanip.cppso the sound “moves” from the left channel to the right channel. The function receives an array of objects of classAudioBuffer, the size of the array, and a pan length that will be applied to theAudioBuffer. For example, ifpan_lengthis88200, the pan should not affect any sample in position88200or higher.Play the
airplane.out.wavrecording. You should be able to listen how the airplane sound starts completely at the left, then slowly moves to the right, reaching the extreme right by the final sample.
Algorithm:
Getting a sound to move from left to right like this requires a fade-out on the left channel and a fade-in on the right channel. For instance, if pan_length is 4, the filter will be applied to the first 4 samples:
| Sample Number | Multiply left channel by factor | Multiply right channel by factor |
|---|---|---|
| 0 | 0.75 | 0 |
| 1 | 0.5 | 0.25 |
| 2 | 0.25 | 0.5 |
| 3 | 0 | 0.75 |
| >= 4 | (Do not modify the sample) | (Do not modify the sample) |
Deliverables
Use “Deliverables” in Moodle to upload the audiomanip.cpp file. Remember to use good programming techniques, include the names of the programmers involved, and to document your program.
References
[1] Daniel Zingaro, http://nifty.stanford.edu/2012/zingaro-stereo-sound-processing/
[2] http://en.wikipedia.org/wiki/Sound
[3] http://homepages.udayton.edu/~hardierc/ece203/sound_files/image001.jpg.
[4] Arbimon, A web based network for storing, sharing, and analyzing acoustic information. http://arbimon.com/
[5] https://somnathbanik.wordpress.com/2012/10/22/digital-signal-processing-featured-project/
[7] http://diveintodotnet.com/2014/12/02/programming-basics-what-are-strings/