
 Jose Ortiz
683f901ea6
initial commit
Jose Ortiz
683f901ea6
initial commit
|
10 years ago | |
|---|---|---|
| data | 10 years ago | |
| doc | 10 years ago | |
| images | 10 years ago | |
| BenfordsLaw.pro | 10 years ago | |
| README.md | 10 years ago | |
| main.cpp | 10 years ago | |
| mainwindow.cpp | 10 years ago | |
| mainwindow.h | 10 years ago | |
| mainwindow.ui | 10 years ago | |
| qcustomplot.cpp | 10 years ago | |
| qcustomplot.h | 10 years ago |
README.md
Arreglos - Ley de Benford
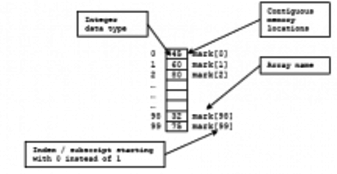

Los arreglos de datos (arrays) nos facilitan guardar y trabajar con grupos de datos del mismo tipo. Los datos se guardan en espacios de memoria consecutivos a los que se puede acceder utilizando el nombre del arreglo e índices o suscritos que indican la posición en que se encuentra el dato. Las estructuras de repetición nos proveen una manera simple de acceder a los datos de un arreglo. En la experiencia de laboratorio de hoy practicarás el uso de contadores y arreglos de una dimensión para implementar un programa en el que usarás la Ley de Benford para detectar archivos con datos falsificados.
Objetivos:
Practicar el uso de un arreglo de contadores para determinar la frecuencia de los datos de un archivo.
Detectar el uso de datos falsificados utilizando la distribución de frecuencia y la Ley de Benford.
Practicar la lectura de datos de un archivo de texto.
Pre-Lab:
Antes de llegar al laboratorio debes haber:
Aprendido cómo extraer el dígito líder (primer dígito) de un número.
Repasado los conceptos relacionados a arreglos y contadores.
Repasado cómo leer datos de un archivo en C++.
Estudiado los conceptos e instrucciones para la sesión de laboratorio.
Tomado el quiz Pre-Lab que se encuentra en Moodle.
Como parte de tu nuevo trabajo de auditora de tecnología de información, tienes la sospecha de que alguien en la Autoridad Metropolitana de Autobuses (AMA) de Puerto Rico ha estado manipulando los sistemas de información y cambiando los archivos de datos que contienen los totales de pasajeros de las rutas diarias de las guaguas. Te han dado 5 archivos de texto que contienen los totales diarios de cada una de las rutas de las guaguas de la AMA y debes determinar si uno o más archivos contienen datos falsos. Para detectar cuál(es) archivos tienen datos falsos implementarás un programa en el que usarás la Ley de Benford.
¿Qué es la Ley de Benford? (adaptado del ISACA Journal [1])
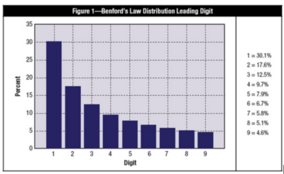
La Ley de Benford es la teoría matemática de los dígitos líderes de un número, y fue llamada así en honor al físico Frank Benford, quién trabajó en esta teoría en 1938. Específicamente, en conjuntos de datos, los dígitos líderes están distribuidos de forma no uniforme. Uno podría pensar que el número 1 aparece como primer dígito el 11% del tiempo (esto es, uno de 9 números posibles), sin embargo, este número aparece como líder alrededor del 30% del tiempo (vea la Figura 1). Por otro lado, el número 9 es el primer dígito menos del 5% del tiempo. La teoría cubre las ocurrencias del primer dígito, el segundo dígito, los primeros dos dígitos, el último dígito y otras combinaciones de dígitos porque la teoría está basada en un logaritmo de probabilidad de ocurrencia de dígitos.
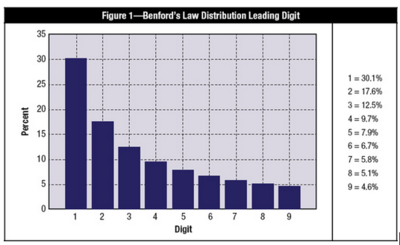
Figura 1. Distribución del primer dígito en un conjunto de datos real según la Ley de Benford. Tomado de [1].
Cómo usar la Ley de Benford para detectar datos falsificados
En esta experiencia de laboratorio usarás la Ley de Benford aplicada solamente al primer dígito (el dígito líder). Para hacer esto, necesitas determinar la frecuencia de cada dígito líder en los números en un archivo. Supón que te dan un archivo que contiene los siguientes números enteros:
890 3412 234 143 112 178 112 842 5892 19
777 206 156 900 1138 438 158 978 238 192
Según vas leyendo cada número $$n$$, determinas su dígito líder (la manera de extraer el dígito líder de un número se deja como un ejercicio para tí). También debes estar pendiente de cuántas veces sale el dígito líder en el conjunto de datos. La manera más fácil de llevar cuenta de la cantidad de veces que aparece el 1 como líder, el 2 como líder, … , el 9 como líder, es utilizando un arreglo de contadores. Este arreglo de contadores es sencillamente un arreglo de enteros en el que un elemento del arreglo se incrementa cada vez que se encuentra cierto dígito líder. Por ejemplo, para este ejercicio el arreglo de contadores puede ser un arreglo de 10 enteros, inicializado a 0.
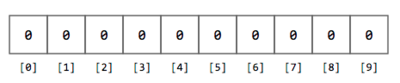
Figura 2. Arreglo de 10 enteros inicializado a 0.
Cada vez que se encuentra el dígito líder d, el elemento con índice d se incrementa. Por ejemplo, luego de leer los números 890 3412 234 143 112, el contenido del arreglo sería el siguiente:

Figura 3. Contenido del arreglo luego de leer 890 3412 234 143 112, y contar sus dígitos líderes.
Al finalizar de examinar el archivo, el contenido de cada elemento en el arreglo será el número de veces que el dígito líder aparece en los datos.
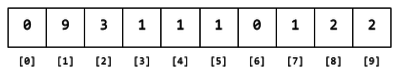
Figura 4. Contenido del arreglo de contadores luego de examinar todos los datos.
Frecuencia de ocurrencia
La frecuencia de ocurrencia se define como la razón del número de veces que un dígito aparece sobre el número total de datos. Por ejemplo, la frecuencia del dígito líder 1 en el ejemplo de la Figura 4 se computa como $$9/20 = 0.45$$. La manera común de visualizar las distribuciones de frecuencia de un conjunto de datos es utilizando un histograma. En esencia, un histograma es una gráfica de barras en la que el eje de $$y$$ es la frecuencia de ocurrencia y se dibuja una barra para cada una de las clasificaciones que se cuenta (en nuestro caso, una barra para cada dígito líder).
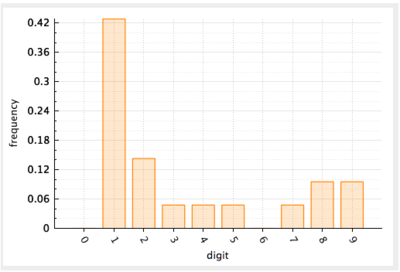
Figura 5. Histograma para la frecuencia de los dígitos líderes en los datos de muestra.
Sesión de laboratorio:
Ejercicio 1: Entender los archivos de datos y el código provisto
Instrucciones
Carga a QtCreator el proyecto
BenfordsLawhaciendo doble “click” en el archivoBenfordsLaw.proen el directorioDocuments/eip/Arrays-BenfordsLawde tu computadora. También puedes ir ahttp://bitbucket.org/eip-uprrp/arrays-benfordslawpara descargar la carpetaArrays-BenfordsLawa tu computadora.Los archivos de datos
cta-a.txt,cta-b.txt,cta-c.txt,cta-d.txt, ycta-e.txten el directoriodatacontienen datos reales o datos falsos. Cada línea del archivo especifica el código de una ruta de guagua seguido por el número de personas que usaron la guagua en cierto día. Abre el archivocta-a.txtpara que entiendas el formato de los datos. Esto será importante cuando leas los datos desde tu programa. Nota que algunos de los códigos de ruta contienen caracteres.Abre el archivo
main.cpp. Estudia la funciónmainpara que te asegures de que entiendes todas las partes. En esencia, la funciónmainque te proveemos crea una pantalla y dibuja un histograma parecido al que se muestra en la Figura 6.
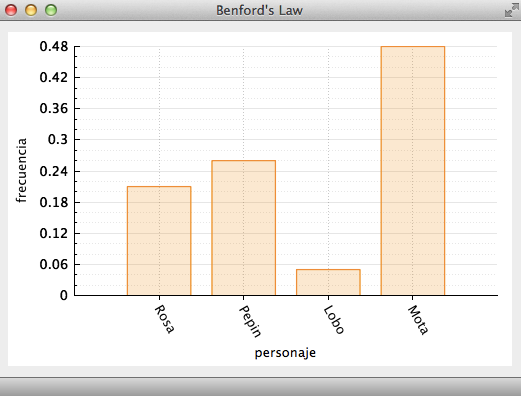
Figura 6. Ventana del resultado del ejemplo provisto en el proyecto
BenfordLaw. Se despliega un histograma utilizando los datos de los argumentoshistoNamesehistoValues.
Nota que los datos para los arreglos
histoNamesehistoValuesutilizados en la invocación al métodohistofueron asignados directamente en la declaración de cada arreglo. Para cada uno de los archivos en el directoriodata, tu programa deberá computar la frecuencia de ocurrencia de los dígitos líderes y luego desplegar su histograma utilizando el métodohisto.
Ejercicio 2: Implementar código para detectar datos falsificados en un archivo
Instrucciones
Utilizando como inspiración la función
mainque te proveemos, añade funcionalidad a la funciónmainpara leer archivos como los provistos en el directoriodatay determinar la frecuencia de ocurrencia de dígitos líderes en los datos que aparecen en la segunda columna de los archivos. Computa la frecuencia de ocurrencia como se explica antes de la Figura 5.Una vez tu programa haya obtenido las frecuencias de los dígitos líderes, utiliza el método
histopara desplegar un histograma. Corre el programa para cada uno de los archivos. Basado en la gráfica de distribución de frecuencia de los dígitos líderes en los datos en cada uno de los archivos, podrás determinar si (de acuerdo a la Ley de Benford) el archivo contiene datos reales o datos falsos.
Entregas
Utiliza “Entrega 1” en Moodle para entregar el archivo
main.cppque modificaste en el Ejercicio 2. Recuerda utilizar buenas prácticas de programación, incluir el nombre de los programadores y documentar tu programa.Utiliza “Entrega 2” en Moodle para entregar un archivo pdf que muestre fotos de los histogramas para cada uno de los archivos. Por favor, subtitula cada figura especificando el archivo que se utilizó para generarla y tu decisión sobre si el archivo contiene data real o falsificada.
Referencias
Arrays - Benford’s Law
Arrays help us to store and work with groups of data of the same type. The data is stored in consecutive memory spaces which can be accessed by using the name of the array and indexes or subscripts that indicate the position where the data is stored. Repetition structures provide us a simple way of accessing the data within an array. In today’s laboratory experience you will practice the use of counters and one dimensional arrays to implement a program in which you will use Benford’s Law to detect files with bogus data.
Objectives:
Practice using arrays of counters to determine data frequency in a file.
Detect the use of bogus data using Benford’s Law and the leading digit frequency distribution.
Practice reading data from text files.
Pre-Lab
Before coming to the laboratory, you should have:
Learned how to extract the leading digit (first digit from left to right) of an integer read from a file.
Reviewed basic array and counter concepts.
Reviewed text file input in C++.
Studied the concepts and instructions for this laboratory session.
Taken the Pre-Lab quiz found in Moodle.
As part of your new job as IT auditor you suspect that someone in the Chicago Transit Authority (CTA) has been tampering with the information systems and changing the data files that contain the bus route daily totals. You are given five text files that contain daily totals for each of the CTA’s bus routes and must determine if one or more of the files contain bogus data. In this laboratory experience you will implement a program that will help you determine which of the file(s) contain bogus data using Benford’s Law, a property that is observed in many real-life sources of data.
What is Benford’s Law? (copied from the ISACA journal)
Benford’s Law, named for physicist Frank Benford, who worked on the theory in 1938, is the mathematical theory of leading digits. Specifically, in data sets, the leading digit(s) is (are) distributed in a specific, non uniform way. While one might think that the number 1 would appear as the first digit 11 percent of the time (i.e., one of nine possible numbers), it actually appears about 30 percent of the time (see Figure 1). The number 9, on the other hand, is the first digit less than 5 percent of the time. The theory covers the first digit, second digit, first two digits, last digit and other combinations of digits because the theory is based on a logarithm of probability of occurrence of digits.
Figure 1. Distribution of the leading digit in a real data set according to Benford’s Law. Taken from [1].
How to use Benford’s Law to spot bogus data
In this laboratory experience you will use Benford’s Law applied only to the leading digit. To do this, you need to determine the frequency of each leading digit in the numbers of the file. Suppose that you are given a file that contains the following integer numbers:
890 3412 234 143 112 178 112 842 5892 19
777 206 156 900 1138 438 158 978 238 192
As you read each number $$n$$, you determine its leading digit (how to extract the leading digit is left as an exercise for you). You must also keep track of how many times the same leading digit appears in the data set. The easiest way to keep track of how many times you find a leading 1, a leading 2, … a leading 9, is to use an array of counters. This array of counters is simply an array of integers where each element is incremented whenever you find a certain leading digit. For instance, for this exercise the array of counters can be an array of 10 integers, initialized to 0.
Figure 2. Array of 10 integers initialized to 0.
Every time a leading digit d is found, the element with index d is incremented. For example, after reading the numbers 890, 3412, 234, 143, and 112, the array content would be:
Figure 3. Contents of the array after reading 890, 3412, 234, 143, 112 and counting their leading digits.
After reading through all the data, the content of each array element will be the number of times that leading digit appears in the data.
Figure 4. Contents of the array after reading all the data.
The frequency of occurrence is defined as the ratio of times that a digit appears divided by the total number of data. For example, the frequency of leading digit 1 in the example would computed as $$9 / 20 = 0.45$$. Histograms are the preferred visualization of frequency distributions in a data set. In essence, a histogram is a bar chart where the $$y$$-axis is the frequency and a vertical bar is drawn for each of the counted classifications (in our case, for each digit).
Figure 5. Histogram of the frequency of leading digits in the example data.
Laboratory session
Exercise 1: Familiarizing yourself with the data files and the provided code
Instructions
Load the project
BenfordsLawonto QtCreator by double clicking the fileBenfordsLaw.proin the folderDocuments/eip/Arrays-BenfordsLawon your computer. You can also go tohttp://bitbucket.org/eip-uprrp/arrays-benfordslawto download theArrays-BenfordsLawfolder to your computer.The text files
cta-a.txt,cta-b.txt,cta-c.txt,cta-d.txt, andcta-e.txtin thedatadirectory contain either real or bogus data. Each line of the file specifies the bus route code and the number of users for that route on a certain day. Open the filecta-a.txtto understand the data format. This will be important when reading the file sequentially using C++. Notice that some of the route codes contain characters.Open the
main.cppfile. Study themainfunction and make sure that you understand all of its parts. In essence, the providedmainfunction creates a window that displays a histogram like the one shown in Figure 6.
**Figure 6.** Result of running the provided program. A histogram is displayed using the data in the arguments `histoNames` and `histoValues`.
---
In the provided code, notice that the data in the arrays histoNames and histoValues were assigned directly in their declarations. For the provided files, your program should compute the frequency of occurrence of the leading digits and then display their histogram by using the histo method.
Exercise 2: Implement a program to detect bogus data in the data files
Instructions
Using the provided
mainfunction as inspiration, add the necessary code to implement a program that reads a text data file like the ones in thedatafolder and determines the frequency of occurrence of the leading digits of the second column of the files. Compute the frequency of occurrence as it was explained before Figure 5.Once your program has the frequency of occurrence of the leading digits, use the method
histoto display the histogram. Run the program for each of the text files. Based on the leading digit frequency distribution for each file, decide if (according to Benford’s Law) the file contains real or bogus data.
Deliverables
Use “Deliverables 1” in Moodle to upload the
main.cppfile with the modifications you made in Exercise 2. Remember to use good programming techniques, include the names of the programmers involved, and to document your program.Use “Deliverables 2” in Moodle to upload a pdf file that contains screen shots of the histograms produced after analyzing each text file. Please caption each figure with the name of the text file and provide your decision as to whether the file contained real or bogus data.